Study of high-fidelity numerical schemes for compressible turbulent flows
JAXA Supercomputer System Annual Report April 2016-March 2017
Report Number: R16E0041
- Responsible Representative: Soshi Kawai(Department of Aerospace Engineering, Tohoku University.)
- Contact Information: Soshi Kawai(kawai@cfd.mech.tohoku.ac.jp)
- Members: Hiroyuki Asada, Soshi Kawai
- Subject Category: Aviation(Body sound)
Abstract
Low-noise devices for reducing airframe noise of aircrafts have been studied and developed in many literature, but the details of interaction between each device are insufficiently investigated. This study develops discontinuous Galerkin (DG) based high-fidelity numerical schemes for compressible turbulent flows around aircrafts to enhance guidelines for designing next-generation low-noise aircrafts by clarifying the details of interaction between each low-noise device.
Goal
The main purpose of this study is to clarify the details of aircraft noise generation, propagation and interaction using a large-eddy simulation (LES) with discontinuous Galerkin (DG) methods and to enhance guidelines for designing next-generation low-noise aircrafts.
Objective
This study develops high-fidelity numerical schemes for high Reynolds number compressible turbulent flows around aircrafts and contributes the research and designing next-generation low-noise aircraft
References and Links
Please refer 'Kawai Lab. - Aerospace Dept., Tohoku University'.
Use of the Supercomputer
Applying the parallelization-friendly DG methods and developing compact time integration schemes to massive parallel computations allows LES computations of aerodynamics noise around whole aircraft configuration, which is informative for guidelines of next-generation low-noise aircrafts.
Necessity of the Supercomputer
The DG methods are known to give high computational cost but also high execution efficiency, so the DG methods work well on massive parallel computations. The massive parallel computing using the super computer is indispensable to realize LES computations around aircrafts using high-order DG methods.
Achievements of the Year
The DG methods give high-order spatial accuracies on unstructured meshes, but LES computations for wall-bounded turbulent flows using the DG methods are few. This is because the restriction on computational time step of explicit time integration schemes becomes more severe increasing the spatial accuracy. On the other hand, conventional implicit time integration schemes are not compact and unable to fully exploit the advantages of DG methods. This study has proposed a cellwise relaxation implicit (CRI) scheme as compact implicit time integration scheme, and recently, iterative compact implicit time scheme to obtain accurate time evolution. The proposed iterative implicit time scheme coupled with high-order DG methods has a possibility to realize massively parallelized LES computations for the flowfields around aircrafts. We first conducted (a)performance assessments of the proposed iterative implicit time scheme on LES computations of wall-bounded turbulent flows. Additionally, in order to enhance the accuracy of spatial integration, we try to develop an energy stable scheme for high-order DG methods which allows no use of Riemann solver. The energy stable scheme is known to be important for LES computations, but the requirements of the energy stable schemes for the high-order DG methods have not been calcified yet. In this study, we first investigate the spatial discretization of the DG + Riemann solver for wall-bounded turbulent flows and requirements of energy stable scheme for high-order DG methods.
(a) Through the computations of turbulent channel flows, we assessed the performances of the proposed iterative implicit time scheme. We showed that, while the conventional CRI scheme gave large phase errors and blow-up of computations, the iterative implicit time scheme gave stable and accurate time evolutions (Fig.1). Additionally, by increasing the number of iterations in the iterative implicit time scheme, we could separately investigate the linearization errors given by implicit time marching procedures with a conclusion that the linearization errors were small when the flowfield was well resolved. The small linearization errors allow to set the number of inner iterations fewer and speedups the iterative implicit time scheme. Furthermore, we showed that the performances are not deteriorated by increasing the spatial accuracy of DG methods. It well indicates that the iterative implicit time scheme is more suitable for higher-order DG methods.
(b) On the computations of turbulent channel flows, we investigated the grid convergence property of DG methods + Riemann solver and requirements of energy stable schemes. It is important for wall-bounded turbulent flow computations to accurately predict streamwise streaks. The present 3rd order DG method + AUSM-DV scheme gave good agreements with DNS solutions by Moser et al. with the computational mesh whose span wise grid size was Δz+=7.9 (Fig.2). Considering the degree of freedom introduced in the DG methods, the span wise grid size was about Δz+=2.6 which is smaller thanΔz+=4.5 used in past computations using a 2nd order central differential scheme. It indicates that the present 3rd order DG method + AUSM-DV scheme gave lower accuracy than the 2nd order central differential scheme, and that the energy stable scheme is indispensable because the Riemann solver was found to give unacceptable dissipation.
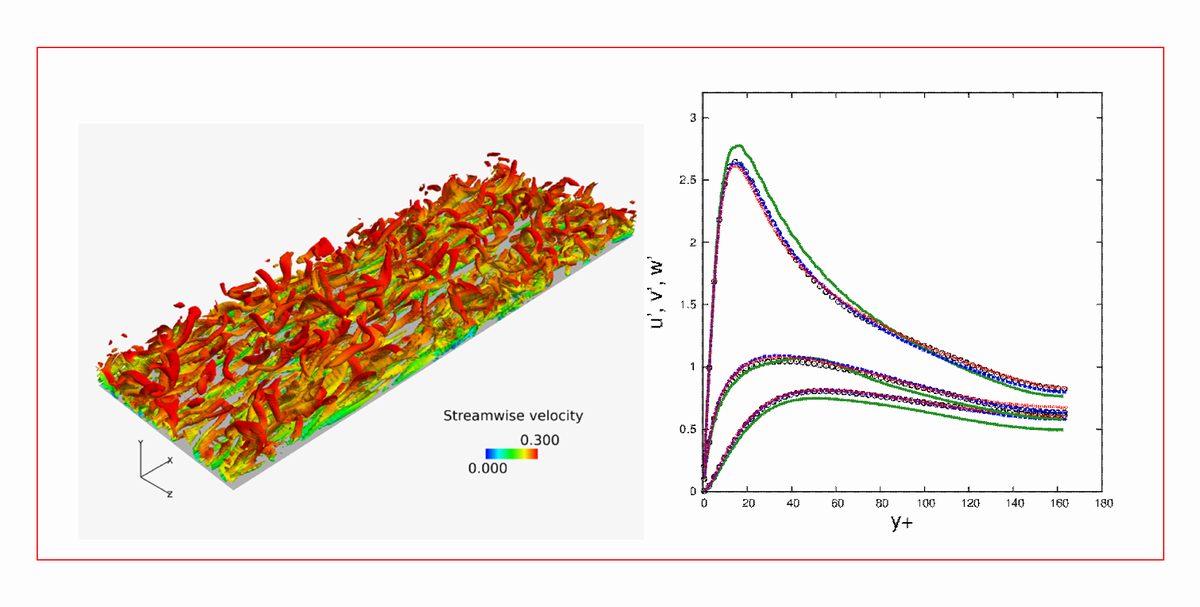
Fig.1:Iso-surfaces of Q criterion and performances of an iterative implicit time integration scheme obtained by the turbulent channel flow computation using high-order DG methods. The number of iterations is 10(green), 15(blue), and 20(red)
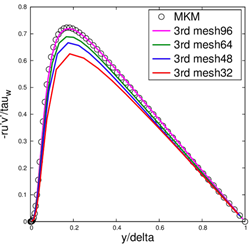
Fig.2:Grid convergence properties of 3rd order DG method + AUSM-DV scheme for turbulent channel flow computations. Reynolds shear stress. A computational mesh is mesh96(Δz+=7.9), mesh64(Δz+=5.1), mesh48(Δz+=3.9), mesh32(Δz+=2.6)
Publications
Peer-reviewed articles
1) H. Asada and S. Kawai 'Requirements of grid resolutions in wall-resolved LES using high-order DG methods', in preparation.
2) H. Asada and S. Kawai, 'A sweep-free implicit time integration scheme for turbulent flow computations with high-order DG methods', Communication in Computational Physics,submitted.
Presentations
1) H. Asada and S. Kawai, 'High-order implicit discontinuous Galerkin scheme for unsteady turbulent flows', AIAA Science and Technology Forum and Exposition, AIAA, Grapevine, Texas, U.S.A., January, 2017.
2) H. Asada, S. Kawai and K. Sawada, 'Requirements of Grid Resolution in Wall-Resolved LES Using High-Order DG Method', European Congress on Computational Methods in Applied Sciences and Engineering (ECCOMAS) 2016, Crete Island, Greece, June, 2016.
Computational Information
- Parallelization Methods: Process Parallelization
- Process Parallelization Methods: MPI
- Thread Parallelization Methods: n/a
- Number of Processes: 300
- Number of Threads per Process: 1
- Number of Nodes Used: 10
- Elapsed Time per Case (Hours): 60
- Number of Cases: 60
Resources Used
Total Amount of Virtual Cost(Yen): 3,820,054
Breakdown List by Resources
| System Name | Amount of Core Time(core x hours) | Virtual Cost(Yen) |
|---|---|---|
| SORA-MA | 2,380,268.60 | 3,798,214 |
| SORA-PP | 0.00 | 0 |
| SORA-LM | 0.00 | 0 |
| SORA-TPP | 0.00 | 0 |
| File System Name | Storage assigned(GiB) | Virtual Cost(Yen) |
|---|---|---|
| /home | 10.73 | 101 |
| /data | 107.29 | 1,012 |
| /ltmp | 2,197.27 | 20,726 |
| Archiving System Name | Storage used(TiB) | Virtual Cost(Yen) |
|---|---|---|
| J-SPACE | 0.00 | 0 |
Note: Virtual Cost=amount of cost, using the unit price list of JAXA Facility Utilization program(2016)
JAXA Supercomputer System Annual Report April 2016-March 2017